NVIDIA两款全新GPU首秀:刷新AI推理纪录、性能314倍于CPU
时隔半年,MLPerf组织发布最新的MLPerf Inference v1.0结果,V1.0引入了新的功率测量技术、工具和度量标准,以补充性能基准,新指标更容易比较系统的能耗,性能和功耗。
V1.0版本的基准测试内容云端推理依旧包括推荐系统、自然语言处理、语音识别和医疗影像等一系列工作负载,边缘AI推理测试则不包括推荐系统。
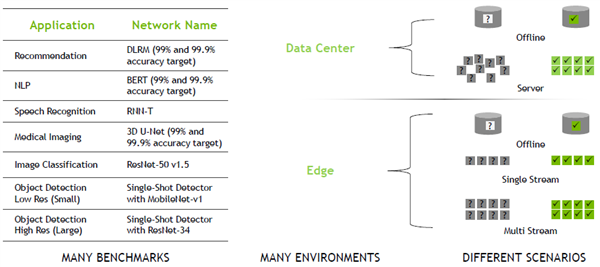
MLPerf Inference v1.0
所有主要的OEM都提交了MLPerf测试结果,其中,在AI领域占有优势地位的NVIDIA此次是唯一一家提交了从数据中心到边缘所有MLPerf基准测试类别数据的公司,并且凭借A100 GPU刷新了纪录。
不仅如此,超过一半提交成绩的系统都采用了NVIDIA的AI平台。
不过,初创公司提交其AI芯片推理性能Benchmark的依旧很少。
AI推理最高性能半年提升45%
雷锋网在MLPerf Inference v0.7结果发布的时候已经介绍过,NVIDIA去年5月发布的安培架构A100 Tensor Core GPU在云端推理的基准测试性能是最先进英特尔CPU的237倍。
经过半年的优化,NVIDIA又将推荐系统模型DLRM、语音识别模型RNN-T和医疗影像3D U-Net模型的性能进一步提升,提升幅度达最高达45%,与CPU的性能差距也提升至314倍。
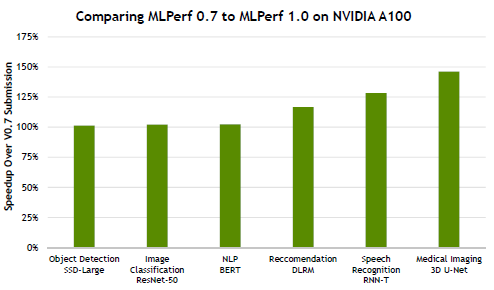
从架构的角度看,GPU架构用于推理优势并不明显,但NVIDIA依旧凭借其架构设计配合软件优化刷新了MLPerf AI云端和边缘推理的Benchmark纪录。
MLPerf的Benchmark证明了A100 GPU性能,但其不菲的售价也是许多公司难以承受的。
今天,更具性价比的NVIDIAA30(功耗165W)和A10(功耗150W) GPU也在MLPerf Inference v1.0中首秀。
A30 GPU强于计算,支持广泛的AI推理和主流企业级计算工作负载,如推荐系统、对话式AI和计算机视觉。
A10 GPU更侧重图像性能,可加速深度学习推理、交互式渲染、计算机辅助设计和云游戏为混合型AI和图形工作负载提供支持。可以应用于AI推理和训练的A30和A10 GPU今年夏天开始会应用于各类服务器中。

A100云端AI推理性能比CPU高314倍
A100经过半年的优化,与CPU的性能差距从v0.7时最多237倍的差距增加到了最高314倍。
具体来看,在数据中心推理的Benchmark中,在离线(Offline)测试,A100比最新发布的A10有1-3倍的性能提升,在服务器(Server)测试中,A100的性能最高是A10的近5倍,在两种模式下,A30的性能都比A10高。
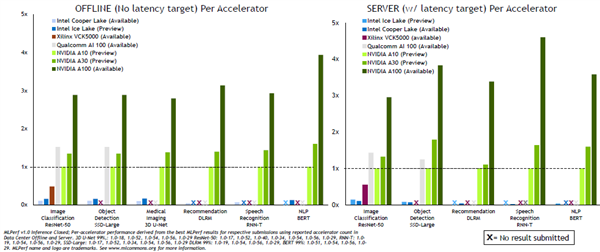
值得注意的是,英特尔本月初最新发布的第三代至强可扩展CPU Ice Lake的推理性能相比上一代Cooper Lake在离线测试的ResNet-50和SSD-Large模型下有显著提升,但相比A100 GPU体现出17-314倍的性能差距。
高通AI 100的云端AI推理在MLPerf Inference v1.0测试下表现不错,其提交的离线和服务器测试下的ResNet-50和SSD-Large模型成绩显示,高通AI 100的推理性能均比NVIDIA新推出的A10 GPU高,其它模型的成绩高通并未提交。
从每瓦性能来看,高通A100在提交成绩的ResNet-50和SSD-Large模型中比A100更高,但性能比A100低。
赛灵思的VCK5000 FPGA在图像分类ResNet-50的测试中表现不错。
Jetson系列是唯一提交所有边缘推理测试成绩的芯片
A系列GPU在云端AI推理的性能优势可以延续至边缘端。MLPerf的边缘AI推理Benchmark分为Single-Stream和Multi-Stream,A100 PCIe、A30、A10在Single-Stream的所有模型下都有显著的性能优势,高通A100在ResNet-50模型下也优势明显,不过高通也仅提交了这一模型的成绩。

这些产品用于边缘AI推理有些大材小用,NVIDIA的Jetson家族的AGX Xavier和Xavier NX更适合边缘场景,根据提交的数据,Centaur公司在ResNet-50模型中优势明显,SSD-Small模型下的性能与Jetson Xavier NX性能相当。
边缘AI推理的Multi-Stream Benchmark,只有NVIDIA提交了成绩,A100 PCIe版本的性能最高是Jetson AGX Xavier和Xavier NX的60倍。
在NVIDIA此次提交的结果中,多项是基于Triton推理服务器,其支持所有主要框架的模型,可在GPU及CPU上运行,还针对批处理、实时和串流传输等不同的查询类型进行了优化,可简化在应用中部署AI的复杂性。

雷锋网(公众号:雷锋网)了解到,在配置相当的情况下,采用Triton的提交结果所达到的性能接近于最优化GPU能够达到性能的95%,和最优化CPU99%的性能。
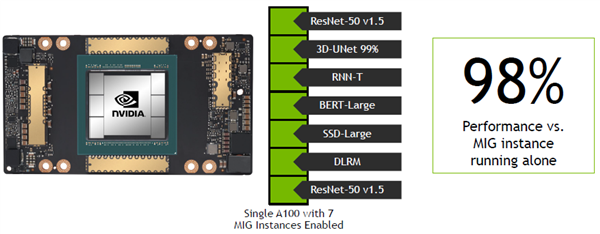
另外,NVIDIA还使用Ampere架构的多实例GPU性能,在单一GPU上使用7个MIG实例,同时运行所有7项MLPerf离线测试,实现了与单一MIG实例独立运行几乎完全相同的性能。
小结
MLPerf Benchmark结果的持续更新,可以为在IT基础设施投资的企业提供一些有价值的参考,也能推动AI的应用和普及。
在这个过程中,软件对于AI性能的提升非常重要,同样是A100 GPU,通过有针对性的优化,半年实现了45%的性能提升。
同时也不难发现,NVIDIA正在通过持续的软硬件优化,以及更丰富的产品组合,保持其在AI领域的领导力,在AI领域想要超越NVIDIA似乎正在变得越来越难。

- THE END -
#NVIDIA#显卡